Robots txt que es
Generador de robots.txt
Puede haber muchas razones por las que quiera personalizar su archivo robots.txt – desde controlar el presupuesto de rastreo, hasta bloquear secciones de un sitio web para que no sean rastreadas e indexadas. Exploremos ahora algunas razones para utilizar un archivo robots.txt.
Bloquear todos los rastreadores para que no accedan a su sitio no es algo que desee hacer en un sitio web activo, pero es una gran opción para un sitio web de desarrollo. Al bloquear los rastreadores ayudará a evitar que sus páginas se muestren en los motores de búsqueda, lo cual es bueno si sus páginas no están listas para ser vistas todavía.
Una de las formas más comunes y útiles de utilizar su archivo robots.txt es limitar el acceso de los robots de los motores de búsqueda a partes de su sitio web. Esto puede ayudar a maximizar su presupuesto de rastreo y evitar que las páginas no deseadas terminen en los resultados de búsqueda.
Es importante tener en cuenta que el hecho de que le haya dicho a un bot que no rastree una página, no significa que no vaya a ser indexada. Si no quiere que una página aparezca en los resultados de búsqueda, debe añadir una etiqueta meta noindex a la página.
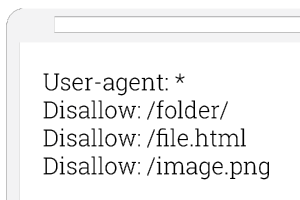
Ejemplo de robots.txt
El archivo robots.txt es uno de los elementos utilizados para la comunicación con los rastreadores web. Los robots buscan este archivo en particular justo después de entrar en un sitio web. Consiste en una combinación de comandos que cumplen con el estándar del Protocolo de Exclusión de Robots, un “lenguaje” que entienden los robots. Gracias a él, los propietarios de los sitios web pueden dirigir a los robots y limitar su acceso a recursos como gráficos, estilos, scripts o subpáginas específicas del sitio web que no necesitan mostrarse en los resultados de búsqueda.
Hace tiempo que los sitios web dejaron de ser simples archivos que no contienen más que textos. La mayoría de las tiendas online incluyen numerosas subpáginas que no son valiosas en términos de resultados de búsqueda o incluso conducen a la creación de contenido duplicado interno (para saber más sobre estas subpáginas, vaya a nuestro artículo anterior sobre contenido duplicado).
Los robots no deberían tener acceso a elementos como los carros de la compra, los motores de búsqueda internos, los procedimientos de pedido o los paneles de usuario. ¿Por qué? Porque el diseño de estos elementos no sólo puede causar una confusión innecesaria, sino que también afecta negativamente a la visibilidad del sitio en las SERP. También debería considerar el bloqueo de las copias de subpáginas realizadas por los CMS, ya que pueden aumentar el contenido duplicado interno.
Robots.txt disallow
Bloquear páginas no públicas: A veces tienes páginas en tu sitio que no quieres que se indexen. Por ejemplo, puede tener una versión de una página en fase de pruebas. O una página de inicio de sesión. Estas páginas deben existir. Pero no quiere que personas al azar aterricen en ellas. Este es un caso en el que se utiliza robots.txt para bloquear estas páginas de los rastreadores y bots de los motores de búsqueda.
Evitar la indexación de recursos: El uso de meta directivas puede funcionar tan bien como el Robots.txt para evitar que las páginas sean indexadas. Sin embargo, las meta directivas no funcionan bien para los recursos multimedia, como los PDF y las imágenes. Ahí es donde entra en juego robots.txt.
Además, si tiene miles de páginas que desea bloquear, a veces es más fácil bloquear toda la sección de ese sitio con robots.txt en lugar de añadir manualmente una etiqueta noindex a cada página.
Fuera de estos tres casos extremos, recomiendo utilizar las meta directivas en lugar de robots.txt. Son más fáciles de implementar. Y hay menos posibilidades de que ocurra un desastre (como bloquear todo el sitio).
Qué es el robots.txt en seo
Robots.txt ayuda a controlar el rastreo de los robots de los motores de búsqueda. Además, el archivo robots. txt puede contener una referencia al mapa del sitio XML para informar a los rastreadores sobre la estructura de URL de un sitio web. Las subpáginas individuales también pueden excluirse de la indexación utilizando la etiqueta meta robots y, por ejemplo, el valor noindex.
El llamado “Protocolo estándar de exclusión de robots” se publicó en 1994. Este protocolo establece que los robots de los motores de búsqueda (también: agente de usuario) buscan primero un archivo llamado “robots.txt” y leen sus instrucciones antes de comenzar la indexación. Por lo tanto, es necesario archivar un archivo robots.txt en el directorio raíz del dominio con este nombre exacto en minúsculas, ya que la lectura del texto de los robots distingue entre mayúsculas y minúsculas. Lo mismo se aplica a los directorios en los que se anota el robots.txt.
Cada archivo consta de dos bloques. En primer lugar, el creador especifica para qué agente(s) de usuario deben aplicarse las instrucciones. A continuación, hay un bloque con la introducción “Disallow”, tras el cual se pueden enumerar las páginas que deben excluirse de la indexación. Opcionalmente, el segundo bloque puede consistir en la instrucción “allow” para complementarlo con un tercer bloque “disallow” para especificar las instrucciones.
