Comprobador de robots.txt
Una araña rastreará un sitio e indexará todas las páginas (que estén permitidas) de ese sitio. Una vez completado esto, el robot pasará a los enlaces externos y continuará su indexación. Así es como los motores de búsqueda encuentran otros sitios web y construyen un índice de sitios tan amplio. Dependen de los sitios web que enlazan con otros relevantes, que a su vez enlazan con otros y así sucesivamente.
Mantenerlo en el directorio raíz garantizará que el robot pueda encontrar el archivo y utilizarlo correctamente. El archivo le dirá al robot qué debe rastrear y qué no. Este sistema se llama “Norma de exclusión de robots”.
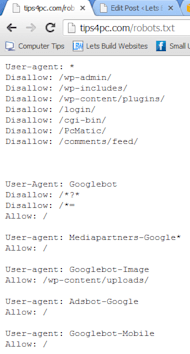
Para la línea de User-agent, usamos un comodín “*” que le dice a todos los robots que escuchen este comando. Así, una vez que una araña lea esto, sabrá que el /cgi-bin/ no debe ser indexado en absoluto. Esto incluirá todas las carpetas contenidas en él.
Especificar ciertos bots también está permitido y en la mayoría de los casos es muy útil para los usuarios que utilizan páginas de entrada u otras formas de optimización de motores de búsqueda. El listado de bots individuales permitirá al propietario de un sitio indicar a las arañas específicas lo que deben indexar y lo que no.
Sintaxis de robots txt
Puede controlar los archivos a los que los rastreadores pueden acceder en su sitio con un archivo robots.txt. Un archivo robots.txt se encuentra en la raíz de su sitio. Así, en el caso del sitio www.example.com, el archivo robots.txt se encuentra en www.example.com/robots.txt. El archivo robots.txt es un archivo de texto sin formato que sigue el estándar de exclusión de robots. Un archivo robots.txt consta de una o más reglas. Cada regla bloquea o permite el acceso de un rastreador determinado a una ruta de archivo especificada en ese sitio web. A menos que especifique lo contrario en su archivo robots.txt, todos los archivos están implícitamente permitidos para el rastreo.
Puede utilizar casi cualquier editor de texto para crear un archivo robots.txt. Por ejemplo, Notepad, TextEdit, vi y emacs pueden crear archivos robots.txt válidos. No utilice un procesador de texto; los procesadores de texto suelen guardar los archivos en un formato propietario y pueden añadir caracteres inesperados, como las comillas rizadas, que pueden causar problemas a los rastreadores. Asegúrese de guardar el archivo con codificación UTF-8 si se le solicita durante el diálogo para guardar el archivo.
Una vez que haya guardado su archivo robots.txt en su ordenador, estará listo para ponerlo a disposición de los rastreadores de los motores de búsqueda. No hay ninguna herramienta que pueda ayudarle con esto, porque la forma de cargar el archivo robots.txt en su sitio depende de la arquitectura de su sitio y de su servidor. Ponte en contacto con tu empresa de alojamiento o busca en la documentación de tu empresa de alojamiento; por ejemplo, busca “subir archivos infomaniak”.
Sitemap en robots txt
Robots.txt es un archivo de texto que los webmasters crean para instruir a los robots de la web (normalmente los robots de los motores de búsqueda) sobre cómo rastrear las páginas de su sitio web. El archivo robots.txt forma parte del protocolo de exclusión de robots (REP), un grupo de normas web que regulan el modo en que los robots rastrean la web, acceden a los contenidos y los indexan, y sirven esos contenidos a los usuarios. El REP también incluye directivas como los meta robots, así como instrucciones para la página, el subdirectorio o el sitio sobre cómo los motores de búsqueda deben tratar los enlaces (como “follow” o “nofollow”).
En la práctica, los archivos robots.txt indican si ciertos agentes de usuario (software de rastreo web) pueden o no rastrear partes de un sitio web. Estas instrucciones de rastreo se especifican “desautorizando” o “permitiendo” el comportamiento de ciertos agentes de usuario (o de todos).
En un archivo robots.txt con múltiples directivas de agentes de usuario, cada regla de desautorización o autorización sólo se aplica a los agentes de usuario especificados en ese conjunto particular separado por saltos de línea. Si el archivo contiene una regla que se aplica a más de un agente de usuario, un rastreador sólo prestará atención (y seguirá las directivas) al grupo de instrucciones más específico.
Ejemplo de robots.txt
Por lo tanto, como propietario de un sitio web, tiene que ponerlo en el lugar correcto de su servidor web para que la URL resultante funcione. Normalmente es el mismo lugar donde se coloca la página principal de bienvenida “index.html” de su sitio web. El lugar exacto y la forma de colocar el archivo dependen del software de su servidor web.
Tenga en cuenta que necesita una línea “Disallow” separada para cada prefijo de URL que quiera excluir — no puede decir “Disallow: /cgi-bin/ /tmp/” en una sola línea. Además, no puede tener líneas en blanco en un registro, ya que se utilizan para delimitar múltiples registros.
Tenga en cuenta también que el globbing y la expresión regular no son compatibles con las líneas User-agent o Disallow. El ‘*’ en el campo User-agent es un valor especial que significa “cualquier robot”. En concreto, no puede tener líneas como “User-agent: *bot*”, “Disallow: /tmp/*” o “Disallow: *.gif”.
Para excluir todos los archivos excepto uno Esto es actualmente un poco incómodo, ya que no hay un campo “Allow”. La manera más fácil es poner todos los archivos que se van a desautorizar en un directorio separado, digamos “stuff”, y dejar el único archivo en el nivel superior de este directorio:
